一、DEMO地址
体验地址:https://liflag.cn/html/tool/wx.html
有时候会有这种需求,将别人的公众号文章“借鉴”为自己的。这时候你会启用f12打开调试工具或者直接将网页保存下来,但微信对图片做了防盗链,只能在自己的域名下使用。所以你还需要把图片保存下来,然后去一一替换文中的图片地址。
显然这个用代码来做,比你手动去改方便很多。所以搞了一个解析微信公众号文章的网页工具,解析公众号文章下载图片和html生成本地可离线浏览的网页副本。
基于这些,甚至还可以直接把文章爬取下来保存到自己的站点中,图片保存到图床中,做一个文章采集的站点
二、使用方法
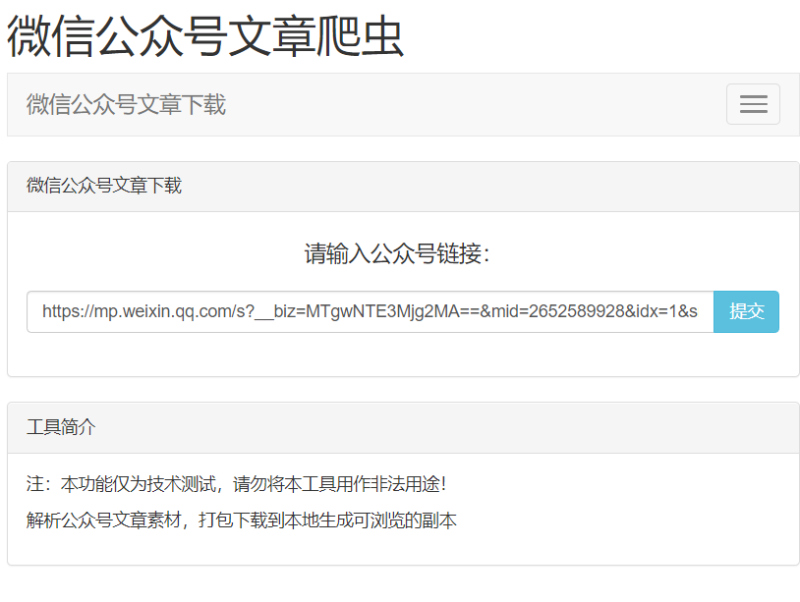
1.输入文章地址
输入地址后台进行解析
2.解析下载压缩包
解析完成后打包到本地

三、主要代码
代码很简单,就用了jsoup解析url和下载图片 如下:
public static void main(String[] args) throws Exception {
String html = getHtml("微信文章url");
File txt=new File("D:/data/test.html");
if(!txt.exists()){
txt.createNewFile();
}
byte bytes[] = html.getBytes();
FileOutputStream fileOutputStream = new FileOutputStream(txt);
fileOutputStream.write(bytes);
fileOutputStream.close();
}
public static String getHtml(String requestUrl) throws IOException {
String startHtml = "<html><head><meta charset=\"UTF-8\"> " +
"<meta name=\"viewport\" content=\"width=device-width,initial-scale=1.0,maximum-scale=1.0,user-scalable=0,viewport-fit=cover\"> " +
"<style>\n" +
" p {\n" +
" text-align: center;\n" +
" font-size: 1.5em;\n" +
" }\n" +
"</style>";
String endHtml = "</div></div></div></div></body></html>";
String endHead = "</head>" +
"<body id=\"activity-detail\" class=\"zh_CN mm_appmsg appmsg_skin_default appmsg_style_default \">" +
" <div id=\"js_article\" class=\"rich_media\"> " +
" <div id=\"js_top_ad_area\" class=\"top_banner\"></div>" +
" <div class=\"rich_media_inner\">" +
" <div id=\"page-content\" class=\"rich_media_area_primary\"> " +
" <div class=\"rich_media_area_primary_inner\">";
Connection connect = Jsoup.connect(requestUrl);
Map<String, String> header = new HashMap<String, String>();
header.put("User-Agent", " Mozilla/5.0 (Android5.1.1) AppleWebKit/537. 36 (KHTML, like Gecko) Chrome/41. 0.2225.0 Safari/537. 36");
Connection data = connect.data(header);
Document doc = data.get();
Elements meta = doc.select("meta");
String viewPort = meta.get(2).toString();
Elements style = doc.select("style");
Elements elements = doc.select("img");
int i = 1;
HashMap<String,String> map= new HashMap<>(32);
String path = null;
for (Element elements1: elements){
String a = elements1.attr("data-src");
if (a != null && !"".equals(a)){
if (map.get(a) == null || "".equals(map.get(a))){
try {
path = download(a, i, a.split("=")[1]);
} catch (Exception e) {
e.printStackTrace();
}
map.put(a,path);
i++;
}
}
}
Elements element = doc.getElementsByClass("rich_media_content");
String html = element.toString();
for (Map.Entry<String, String> entry: map.entrySet()){
html = html.replace(entry.getKey(), entry.getValue());
}
html = html.replace("data-src", "src");
String resultHtml = startHtml + viewPort + style.toString() + endHead + html + endHtml;
return resultHtml;
}
public static String download(String urlString, int i, String suffix) throws Exception {
// 获取URL并构造URL
URL url = new URL(urlString);
// 打开URL连接
URLConnection con = url.openConnection();
// 定义输入流
InputStream is = con.getInputStream();
// 定义1K的数据缓冲
byte[] bs = new byte[1024];
// 读取到的数据长度
int len;
/**
*
* 设置输出的文件流并设置下载路径及下载图片名称
*/
String filename = "D:\\data\\\\test\\" + i + "." + suffix;
File file = new File(filename);
FileOutputStream os = new FileOutputStream(file, true);
// 开始读取
while ((len = is.read(bs)) != -1) {
os.write(bs, 0, len);
}
// 下载完毕,关闭所有链接
os.close();
is.close();
return filename;
}
注意:本文归作者所有,未经作者允许,不得转载