
新建一张表:
CREATE TABLE LSQ_TEST_TABLE (
ID VARCHAR(64) NOT NULL COMMENT '主键',
NAME VARCHAR(10) COMMENT '姓名',
CLASS VARCHAR(10) COMMENT '班级',
YUWEN VARCHAR(10) COMMENT '语文',
SHUXUE VARCHAR(10) COMMENT '数学',
ENGLISH VARCHAR(10) COMMENT '英语',
PHYSICS VARCHAR(10) COMMENT '物理',
CREATTIME VARCHAR(19) COMMENT '创建时间',
PRIMARY KEY (ID),
INDEX IDX_NAME (NAME)
)ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='测试表';
插入几条数据后,查询结果:
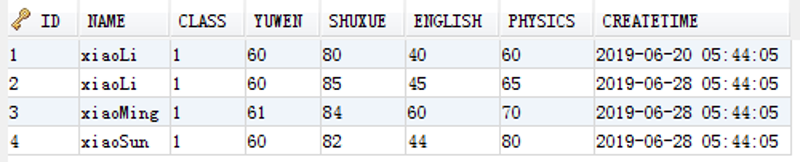
现在我的查询需求是得到NAME和YUWEN去重的结果。
group by或者distinct 分组
传统的办法是采用group by或者distinct关键字,看下面:
select NAME, YUWEN FROM lsqsit.lsq_test_table GROUP BY NAME, YUWEN;
select distinct NAME,YUWEN FROM lsqsit.lsq_test_table ;
两条SQL执行结果都为:
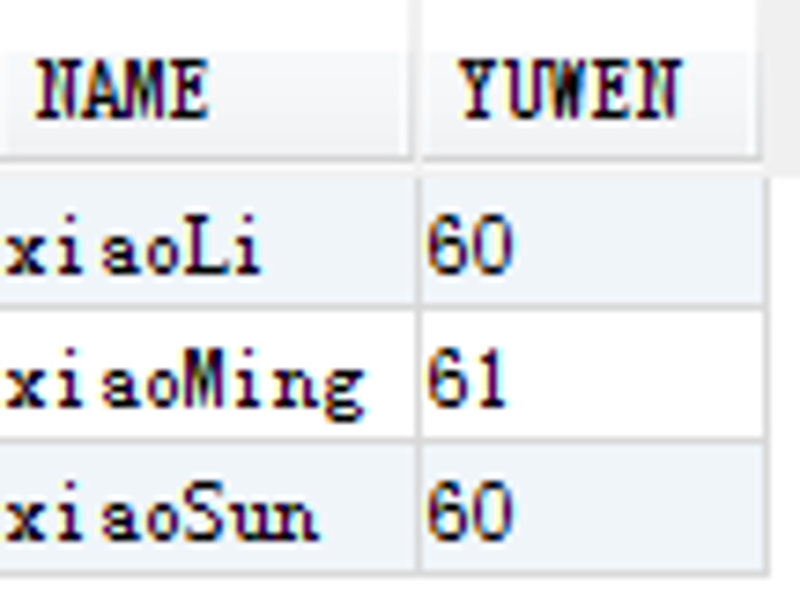
这种方式的缺点是无法得到其他字段的值。
下面有两种方式可以解决这个缺点:
方法1:使用ANY_VALUE()字段
SQL如下:
SELECT ANY_VALUE(ID),ANY_VALUE(NAME),ANY_VALUE(YUWEN),ANY_VALUE(ENGLISH),ANY_VALUE(SHUXUE),ANY_VALUE(PHYSICS),ANY_VALUE(CREATETIME) FROM lsq_test_table where lsq_test_table.CLASS = "1" GROUP BY NAME, YUWEN;
这个查询到的结果为:

方法2:使用组合查询
思路是:①首先根据排重字段NAME和YUWEN进行group by,然后对group by的每个结果去最大id,即MAX(id);②然后从主表中找到这些id的记录
SELECT id,name,yuwen,shuxue,english,physics,createTime FROM lsq_test_table WHERE id
IN(SELECT MAX(id) FROM lsq_test_table where CLASS = "1" GROUP BY NAME, YUWEN)

注意:发现重复的记录取的是id最大的那个。
两个方法对比: 方法1只会对数据库查询一次,而方法2会查询库两次; 方法2中in()函数没有索引,因此如果你id数量足够多的话,那么查询会很慢;
oracle支持 ANY_VALUE 函数
同理在oracle 中 也支持这两种方式,但在Oracle 19c才开始支持 ANY_VALUE 函数
注意:本文归作者所有,未经作者允许,不得转载

